关于 MYViki 网站的一切
前言
2025年9月28日,马来西亚中文 VTuber 互助会的资讯正式解禁,于此同时 MYViki 也第一次向大众公开。历经4个月的独自开发,绞尽脑汁构思的实现的种种功能,熬夜数次将 VTuber 们的资料尽可能地全面收集并输入数据库,终于能看到成品见光的这一天。作为开发者,我有许多功能设计与开发上的心得想要分享给大家,由此写了这一篇文章。
初衷
2020年,我曾以异世界公会的名义构建了一个网站,当中有一个页面便是列出了所有马来西亚的中文 VTuber。当时仅仅只是想要能直观看到 VTuber 名单的网页,方便展示给对这个圈子陌生的圈外人。后来我得知,其实有很多人都会用这个网站来展示和查找 VTuber,他们也表达出「对想要推广 VTuber 文化的人而言特别方便」的评价。
那个网站在后来因事业忙碌无法抽身,以及该项目代码难以维护(这是我第一次写的网站项目),我便在2023年将网站关停了。
在那之后,我虽然鲜少以 VTuber 身份活跃在前线,但仍会持续关注圈子的发展。在我观察圈子的这几年来,我发现新人和前辈之间的交集越来越少,圈内人甚至都难以知晓有哪位新人已经出道了。VTuber 之间的凝聚力逐渐式微,而新人越来越难以获得社区流量的加持得以被看见。
发现这个问题的人并不只有我一个。
在今年的6月,NAGi 向我委托了网站构建的项目,一个收录并展示马来西亚中文 VTuber 资讯的网页,同时也向我透露了关于「马来西亚中文 VTuber 互助会」的企划。当下我便意识到,和我有同样想法的人一定有很多,并且大家其实都想为这个社区贡献一份力量。在仔细聆听 NAGi 所筹备的企划之后,我毫不犹豫答应了这个委任工作,并且以无偿的方式接下这项委托。
这个企划需要莫大的心力和时间去完成,她的决心让我感到既意外又欣慰。我们都看到了社区发展的瓶颈,并且不打算止步于此。也许,建立这个网站是在这个圈子里只有我能去做的事情。
功能介绍
目前类似 VTuber 数据库的网站其实有很多,能够参考像是 Hololist 以及 Portal:VirtualCreator 这样的网站。NAGi 的诉求是能展示本地中文 VTuber 的页面,并且能简单地找到每个人的资讯。这个部分难度并不大,很快就做出了基本的网站架构了。在动手开发的过程中冒出了更多有意思的想法,例如打开主页便能快速浏览最近的直播内容,或是最新的企划活动资讯等。
于是我构思出网站目前主要的功能:
- 能从主页中直接获取最新的资讯(主页)
- 用直观的方式展示所有 VTuber(VTuber 一览页面)
- VTuber 资料展示(VTuber 个人页面)
- VTuber 最新影片列表(影片页面)
- VTuber 相关的企划活动收录(活动页面)
关于主页
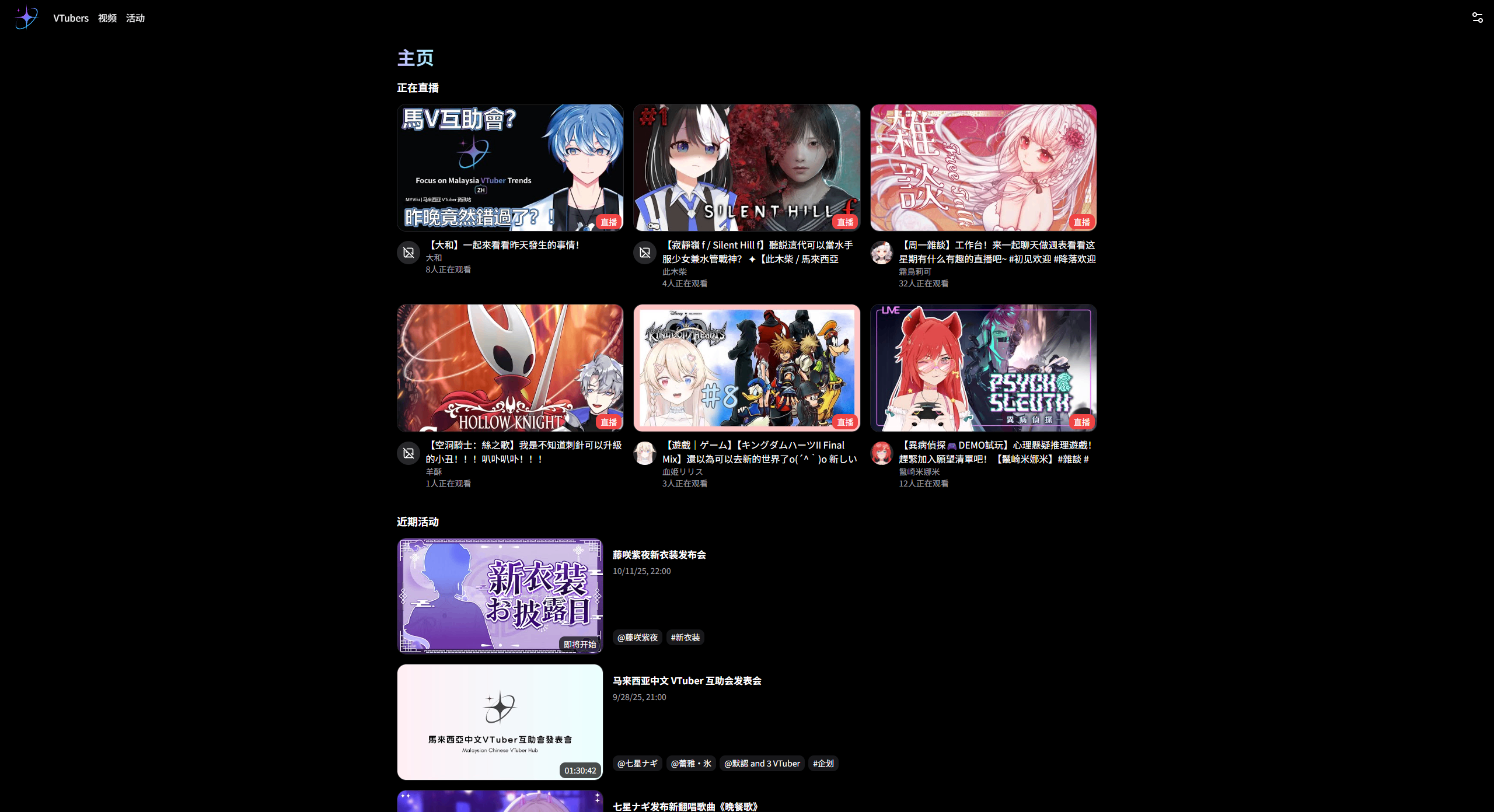
主页是用户打开网站看到的第一页,我认为在这里可以尽可能展示观众最需要的资讯,比如当前正在直播或是即将开播的影片、最近有什么特别的企划资讯,以及今天是哪位 VTuber 的生日。
关于 VTuber 页面
展示所有本地中文V的目录,提供搜索功能,以及能按订阅数、名字、出道日排序。个人资料页面能够展示重要的讯息,例如订阅数、简介、人设等。
这个部分需要人力去收集并更新资料,NAGi 自主收集了六十几位 VTuber 的主要资料(名字、社群链接、立绘等)并提供给我,我再将这些数据导入到数据库中。后来我认为能够展示的讯息其实还有很多,比如粉丝名、Oshi-mark、Hashtag等,因此我又从大家的频道简介中获取这些资讯并更新(如果频道简介没有这些资讯就没有啦)。
Note
目前 VTuber 个人资料的维护采取 VTuber 本人自主更新的方式,想要更新自己的资料可以联系蕾雅・氷和藤咲紫夜加入互助会 Discord,并在 MYViki 频道中提交资料即可。
关于影片页面
在这里能获取所有已收录的 VTuber 的 YouTube 影片,并且透过顶部的分类也能迅速找到正在直播或是即将直播的影片列表。
影片是自动透过 YouTube APIs 抓取的,由于 YouTube 的限制,我无法高频率地同步所有频道的影片数据。因此我制定了这样的同步策略:
- 每小时抓取一次所有频道最新的50个影片,包括即将直播的影片数据。如果直播影片是突发的,可能会错过这次抓取,需要等到下一个周期才能被收录。
- 每天抓取一次所有频道的所有影片,用于对齐数据库中的影片数据,所以如果 VTuber 将影片设为不公开或删除时,可能需要等到马来西亚时间0点才会更新。
- 每分钟抓取当前正在直播或是3小时内即将直播的影片数据,为了及时获取直播状态(例如是否开播,同接数等)
向 YouTube 抓取影片数据消耗的配额是相当可观的,我正在尝试向 Google 申请更高的配额以实现把每小时抓取一次缩短到每五分钟一次,这样比较能保证直播影片数据的及时性。
关于影片分类,未来我会尝试特别收录翻唱影片的分类,虽然这部分会特别耗费心力……
关于活动页面
在这里能获取马来西亚中文 VTuber 相关活动的最新资讯,收录的事件类型有:
- 订阅里程碑(条件:1000以上且第一位数发生变化,例如:1000、2000... 10000、20000)
- 大型企划(多人联动企划)
- 线下活动(漫展演出、漫展多人合作摊位)
- 歌曲影片发布
由于活动事件收录全靠人力进行,我会筛选较为重要的事件收录。
Note
如果你是 VTuber 并且正在筹划和马来西亚中文 VTuber 相关的企划活动,可以在互助会 Discord 的 MYViki 频道中提交相关资料告诉我们!
未来
虽然开发也占据不少心力,但一个开发程序应用真正的挑战其实是后续的维护更新。考虑到互助会项目组内的成员都没有这方面的经验,未来很长一段时间都会是我一个人更新 VTuber 的资料以及活动事件的收录。如果真的忙不过来,关于数据更新的部分我会尝试让其他人帮助维护,而我就专注在网站功能上的更新即可。
未来会开发怎样的功能尚未可知,我想我会选择尽可能让观众用户更加便利地获取资讯的功能路线,去除花里胡哨的内容,专注在服务推广 VTuber 和推送资讯上。
技术选型
接下来我想分享关于开发网站的内容,看不懂的同学可以离开了~
| 技术 | 注释 |
|---|---|
| PocketBase | Database Backend |
| MinIO | S3 Object Store |
| Bun | Server Runtime |
| Caddy | Web Server |
| Umami | Tracking and Analytics |
| Vite | JS Bundle |
| Amateras | Front-end Library |
数据库
针对这次的项目,关于数据库的选择其实思考了很久。考虑到这些 VTuber 数据可能会经常需要手动增删改,以及操作数据的人员可能未必掌握了编程相关的经验,只使用传统数据库可能会让效率降低许多。为此,我想找到一个能够可视化操作数据的方案。
认识你很高兴,Supabase
Supabase 是我第一个尝试的方案,作为第一次使用这类工具的我,开始惊叹于这类技术所带来的便利性。创建一个表,设置 property 类型,然后填入数据。就这样,你就可以从外部直接透过 API 访问到这些数据了,不用架设一个 Database 或是数据伺服器,也无需处理繁杂的数据类型。而且 API 相当简单直接,也有现成的库可以更便利的调用。
由于找到的替代方案不多,Supabase 差点就成为这次项目的数据库方案了。但在我准备敲板定案时,0nepeop1e 介绍了我一个工具,认为我应该尝试使用它,这就是 PocketBase。
更小巧的 PocketBase
PocketBase 整体功能和 Supabase 相比并不会很丰富,它只提供了最核心的 Collection(也就是 Supabase 的 Table)。整体功能非常简单,并且最重要的是它不像 Supabase 那样需要创建一个账号,把所有数据都放在云端。它是能够 Self-hosting 的开源数据库后端,这意味着更高的效率以及自主性。
而我确实在使用 Supabase 的时候,感受到这是一个相当臃肿的服务。UI 相当复杂,提供了一堆我并不需要的功能,并且操作数据时响应速度慢得可怕,仅仅是用了几次就让我感受到些许不耐烦。相反的,PocketBase 简直让我眼前一亮。没错,我仅仅只需要一个功能,那就是数据管理!
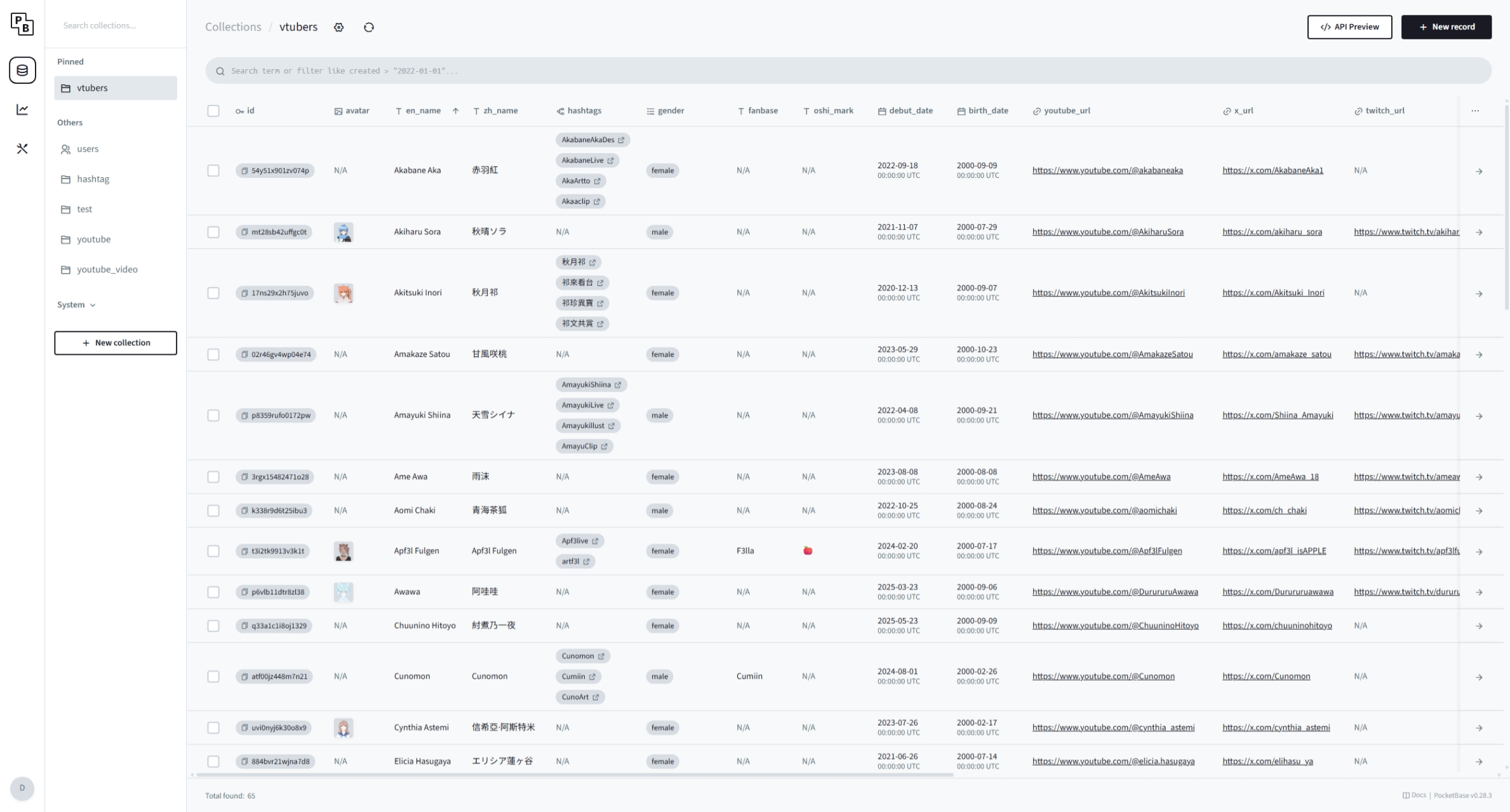
PocketBase 专注于这一点,提供了更多更便利的功能。例如更丰富的数据类型,支持图片上传并自动生成多个大小不同的缩图(可自定义)等。尤其是图片处理的部分,直接成为我选择这个数据库后端的主要原因,因为 MYViki 需要展示 VTuber 的图片,而自动处理缩图可以让我的数据操作过程更轻松,我的网页能够加载缩图来减轻流量负担!
PocketBase 的图片上传需要自行设置 S3 Object Store 的方案,而我正好已经部署了 MinIO 在我的伺服器上。前置科技树已经点亮,轻松解锁这项功能。
在使用 PocketBase 操作数据时,所有的一切都非常的快速。很轻松的建立了我的第一个数据表格,让我能直接展开我的前端编程工作。当然,它也提供了 JS 的库,可以在 Client 和 Server 环境下直接调用。但为了网页的文件体积,Client 环境下我还是使用 API 网址获取数据,好在它的 API 非常简单,也有提供丰富的文档让我方便理解。
总而言之,PocketBase 算是让我对操作和存储数据有了崭新的愉快体验。
后端
我需要一个伺服器来实现以下功能:
- 定时更新每个 VTuber 的 YouTube 频道和视频数据
- 优化 SEO
以上的功能使用 Bun 和 Caddy 就足以应付,这些都是我日常使用的工具。
流量数据分析
在之前我都会使用 Google Analytics 来分析访问网站的用户分布在什么地区、使用什么浏览器版本、装置类型等基本资讯来帮助我更好的优化网站的用户体验。但在某人(就是你 0nepeop1e)的熏陶下,我认为 Google Analytics 多少有点过于侵犯隐私问题了。而我想尽可能避免使用 cookies 来达到数据分析的功能,在翻遍各大论坛的帖子后,我从 Reddit 的某个帖子中发现了 Umami。
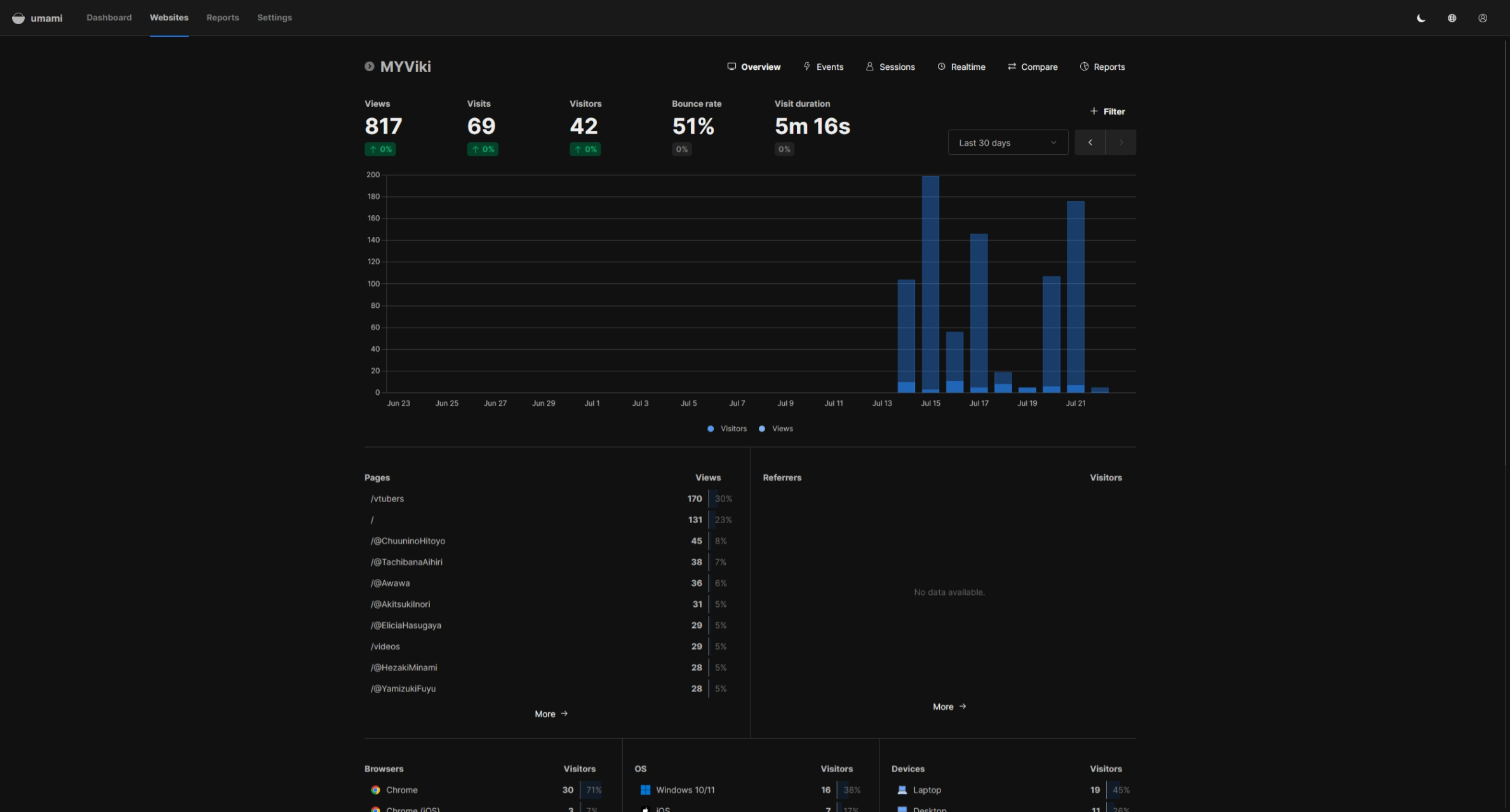
Umami 也是一个能够 Self-hosting 的开源工具,使用 Docker 部署起来非常轻松。其实我对流量数据分析工具并没有很透彻的理解和应用,仅仅只是需要能进行流量计算和用户分布报告的工具,而 Umami 将这一点做的非常好。其操作界面非常简洁直观,也没有臃肿的无用功能,体验非常好。
前端
作为一个前端框架自主开发狂魔,本次使用的是自己开发的网页工具库 Amateras,而这个库甚至才刚诞生不到两个月!但我对这个库却相当有信心,并以极快的速度将它投入到实战应用中。
Amateras 的前世今生
这个库的核心概念继承自我的前一个自主开发的框架 ElexisJS。此框架已经在各种项目中被投入使用,长期下来对网页开发核心要素的理解逐渐更加成熟之后,我意识到这个所谓的「框架」还是太臃肿了。我所追求的不是一个要开发者遵循各种规则的「网站框架」,而是能配合 JS 这个独特语言的特性进行开发的「网页工具库」。我要一个体积更小,构建的核心逻辑更自洽,效率更高,能应用到大部分需要进行网页元素构建场景的工具。
由此,Amateras 诞生了。
Just in JS,前所未有的优雅
这个库的目标是将网页构建这件事可以用 JS 处理得更轻松,不是 JSX 而是原生的,纯粹的JS。虽然这个做法在当今前端框架群魔乱舞的时代并不稀奇,但与 React 等使用 Virtual DOM 构建网页的框架不同,我仅仅只是简化了使用原生 JS 构建元素和置入元素的方法,让开发者自行决定元素的变化,操作的是真正的DOM。
import 'amateras';
$(document.body).content([
$('h1').class('title').content('Hello, World!')
])
这段代码展示了如何在 <body> 元素中创建并内置一个新的 <h1> 元素。如果你学习过 jQuery,可能会以为 $() 是一种选择元素的函数,但它其实和 jQuery 是完全不一样的逻辑。
创建、置入和操作,这就是我对开发网页的核心理解。也许写好一个模板并让框架内核帮你处理 DOM Diff 的方法可以让你更迅速构建一个网站,但其所带来的性能消耗并不能让你成为一个更好的前端开发者。我认为知晓元素的位置和状态,并以此为前提去操作元素改变网页内容,才是一个合格的前端开发者所应具备的能力。
All in JS,真正的效率
不只是替代了 HTML 的工作,就连 CSS 的样式设计工作也能够被取代。Amateras 能够单独为每个元素设定好 CSS 样式,其操作速度远超你的想象。
import 'amateras';
import 'amateras/css';
$(document.body).content([
$('h1').css({ fontSize: '2rem' }).content('Hello, World!')
])
上面这段代码会为 <h1> 元素单独创建一个 CSS 规则并设定一个随机 class 名字,开发者不需要再思考为不同组件使用不同的 class 名字,这些样式规则也遵循先来后到的机制,摆脱了 CSS 痛苦的 Selector 优先级规则。
超乎想象的极小体积
这个工具围绕着少即是多的原则,将多个功能进行分类与模组化。在巧妙地实现了便捷的 API 的同时,核心代码仅有 5.50 kB(gzip 2.32 kB) 的体积。这已经比大部分前端工具还要小了,对此我感到非常满意。
即使包含了 css 和 router 等模块,MYViki 首页的所有代码(依赖包+业务逻辑)总量也只有 27.49 kB(gzip 10.62 kB)而已。
小结:持续进化的工具库
当然,作为第一次投入进实战的工具,必然有很多尚未考虑的问题和 Bugs。但其实这些问题很快都会迎刃而解,毕竟类似的开发已经经历很多遍了。相反,我对这个工具的满意度仍在不断提高,这大概是我至今开发过的项目里,各方面技术含量最高的杰作了。
开发中遇到的问题
YouTube Data API,我曾经的噩梦聚合体,让我撞墙无数次的接口使用体验。坦白说,我接触的 API 类型确实不能算多,但 YouTube Data API 确实是我接触过的 API 当中最让我感到棘手和数据不完整的 API。接下来我将带你一步步了解我是如何透过这个 API 构建出我的数据模型:
本次项目需要的数据:频道数据(ID,名字,订阅数,视频等)视频数据(ID,标题,封面图网址,点赞数,观看数,同接数等)
获取频道数据
我的 VTuber 数据库中已经记录了每个 VTuber 的 YouTube 频道网址,因此我能够直接使用网址后面的 Handle(也就是@开头的 ID)来获取每个 VTuber 的频道数据。这一步并没有难度,我也顺利得到了第一批数据。
但也在此时,我隐隐约约开始担忧一件事,那就是 API Quota。大部分 API 都会限制一个账号能够访问 API 的次数,而 YouTube 清晰的列出了所有规则。
- 每天只有 10000 个单位的 Quotas(可申请扩增)
- 大部分查询只需要消耗 1 个单位
search需要消耗 50 个单位- 在一次查询中可包含最多50个相同类型的数据
假设有100位 VTubers,如果我要每分钟更新一次订阅数,那就需要查询两次,每天消耗的单位为:60m * 24hr * 2 = 2880units/day。
Tip
值得一提的是,如果用 Handle 进行查询是无法实现一次查询50个频道数据的,因此必须先存储每个频道的ID后再进行查询。
获取视频数据
接下来,我需要获取每个频道的视频数据,而这里便是麻烦的源头。
YouTube API 把一个频道的所有视频都视为一个 Playlist 当中的视频,所以我们需要先把每个频道的 PlaylistItems 数据都抓取一次,才能获得这个频道的所有视频。
Tip
一个小技巧,每个播放列表都有一个ID,而作为包含所有该频道视频的列表的ID与该频道的ID相同,只需要把频道ID开头的UC字串改成UU即可。
一个频道可能有上百个视频,由于一次查询只能获取50个结果,因此每个频道可能需要2~5次不等的查询次数。
并且,查询 PlaylistItems 接口所得到的视频数据结果并不完整,当中不会包含这个视频的直播数据 liveStreamingDetails。因此还需要再使用 Videos 接口查询多一次来获取完整数据。
同样假设有100位 VTubers,每个 VTuber 的频道有150个视频,如果我需要每小时抓取所有视频的数据,那每天消耗的 Quota 单位为:24h * (150videos / 50) * 2 * 100 = 14400units/day。
直接炸裂,这个频率明显不太可能实现。虽然可以透过向 Google 申请扩增 Quota,但当中要求的条件和要经历的流程让我非常不想面对,如无必要我就先将就用着。
因此我只好放弃同步所有视频数据,而是只在首次抓取所有视频,之后每小时更新最新50个视频。每天消耗的单位为:((150videos / 50) * 2 * 100) + (23h * (50videos / 50) * 2 * 100) = 5600units/day。
其实每小时获取一次频道的视频数据是相当不足的,我想要在 MYViki 网站上展示当前正在直播的数据,但有些直播并不会提早开设直播间而是临时突发,一小时的间隔让我无法更加实时的得到这些新直播视频的数据。
获取直播数据
最后,我还需要追踪当前正在直播或是即将直播的视频数据。这个数据需要更高频率的更新以便不错过准确的信息,我决定以每分钟一次的频率去追踪这些数据。
筛选出正在直播和即将直播的视频,然后再以每分钟一次的频率访问 Videos 接口获取视频数据。好消息是,一般上同时直播的频道不会太多,甚至有时候根本没有正在直播的频道,这能大幅缓解 Quota 限制的压力。
假设同时正在直播和在未来3小时内即将直播的视频总数为50个,每分钟抓取一次,所消耗的单位为:(50videos / 50) * 60m * 24h = 1440units/day。
小结:关于 Quota 限制
以目前马来西亚中文 VTuber 的数量来说,这个 Quota 限制还不至于造成太大压力。但尽管这些是比较极限的理论值,每天消耗的单位为 9920units,已经很逼近限制了。未来若真的需要,还是会向 Google 申请更多的 Quota 上限。
关于 YouTube Data API 的坑
如果你以为搞定频率和 Quota 限制就能解决问题,那可真是大错特错。这个 API 尽管经历了多次更新,也仍然有许多莫名其妙的缺陷。比如:我根本无法真正知道这个视频到底是上传视频还是直播视频。
前面提到的 liveStreamingDetails,不只会出现在直播视频中,也会出现在一部分上传视频中。因为 YouTube 有一个 Premiere 视频机制!这个机制会在视频首播时以直播的形式进行放送,而 YouTube API 并不会标注这是一个 Premiere 视频来和直播视频做区分!
相信我,我已经翻遍整个网络,都没人能彻底只靠 YouTube API 解决这个问题,连 AI 都推荐我用「抓取视频网页上的 Premiere 字眼来得知视频的类型」这种没文化的方式来解决问题。在历经3小时的挣扎后我放弃去做任何分类了,就这样放着不管吧。
结尾
由于这是一个以兴趣为驱动力进行的项目,整个过程虽然碰上不少问题,但我都能饶有兴致的去解决它们。甚至这个项目也成为了我的工具库的试金石,让这个库变得更加完善可靠。
希望这个网站真的能更好的推广马V,也能成为观众获取信息的一个实用工具。